Implementing Tomasulo’s Algorithm: A Deep Dive into Modern Processor Design
Modern processors perform a complex dance of instruction execution, managing dependencies and resources while maintaining program correctness. At the heart of this orchestration lies Tomasulo’s Algorithm, a remarkable solution for out-of-order execution that has stood the test of time. In this post, I’ll walk through my implementation of this algorithm in SystemVerilog, sharing insights and lessons learned along the way.
Understanding the Architecture
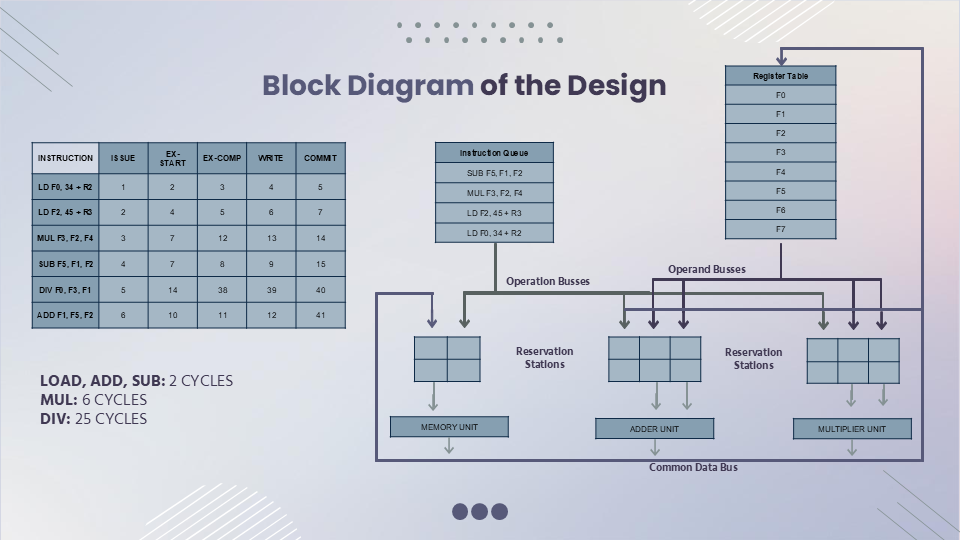
The implementation focuses on creating a flexible and efficient out-of-order execution unit. At its core, the design processes 12-bit instructions, managing them through various stages from issue to commit while handling dependencies and resource constraints.
Instruction Format
Each instruction is encoded in 12 bits:
- 3 bits for opcode
- 3 bits for destination register
- 3 bits for first source register
- 3 bits for second source register
Processing Units
The design implements three main functional units:
-
Load/Store Unit
- Two-cycle latency
- Two reservation stations for concurrent operations
-
Add/Sub Unit
- Two-cycle latency
- Two reservation stations enabling parallel execution
-
Multiply/Divide Unit
- Multiplication: 6-cycle latency
- Division: 25-cycle latency
- Two reservation stations for parallel operations
Verification Environment
The verification environment follows a structured, layered approach that enables comprehensive testing while maintaining modularity and reusability. Here’s how the components work together:
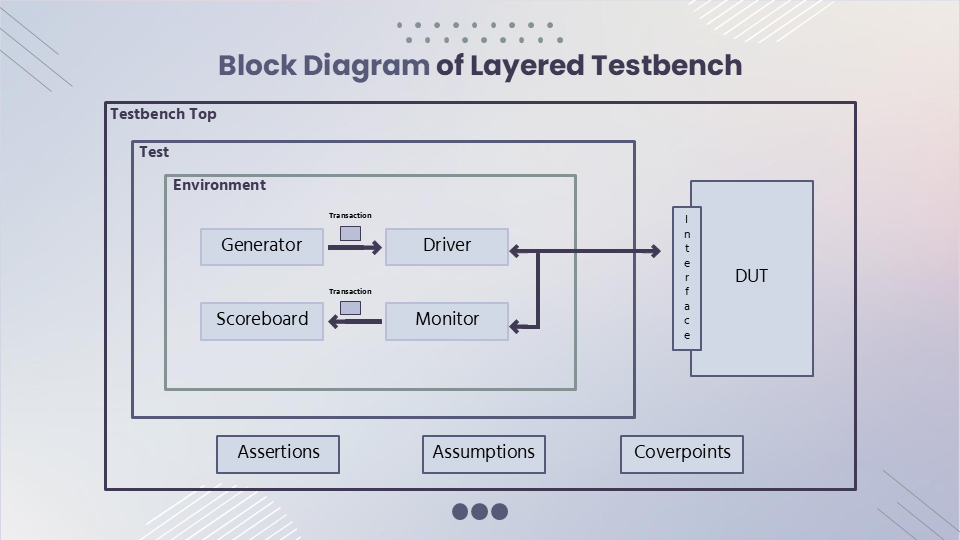
Testbench Components
-
Interface
- Defines the communication protocol between testbench and DUT
- Encapsulates all design signals
- Provides a clean abstraction layer for verification components
-
Transaction Class
- Defines the instruction packet structure
- Implements randomization with constraints
- Enables easy manipulation of test scenarios
-
Generator
- Supports both constrained-random and directed testing
- Configurable instruction generation patterns
- Enables systematic coverage of corner cases
-
Driver
- Translates transactions into pin-level activity
- Implements protocol-compliant signal driving
- Ensures proper timing of instruction delivery
-
Monitor
- Captures design outputs and state changes
- Performs signal-level protocol checking
- Provides abstraction for higher-level analysis
-
Scoreboard
- Implements the reference model
- Performs result comparison and validation
- Generates execution timelines for analysis
-
Environment
- Manages verification component instantiation
- Coordinates test execution flow
- Handles configuration and resource management
-
Test
- Implements specific test scenarios
- Controls test execution parameters
- Provides configuration for different verification goals
-
Testbench Top
- Instantiates and connects all components
- Manages simulation flow
- Handles initialization and cleanup
-
Assertions
- Implements protocol and functionality checks
- Monitors critical design properties
- Ensures design invariants are maintained
-
Coverage
- Tracks functional coverage metrics
- Implements coverage groups and bins
- Guides verification completion assessment
Coverage Results
The verification effort achieved comprehensive coverage across multiple metrics:
Overall Coverage: 89.69%
- Block Coverage: 91.02%
- Expression Coverage: 66.16%
- Toggle Coverage: 97.38%
- Assertion Coverage: 81.10%
- CoverGroup Coverage: 78.59%
These results demonstrate thorough verification of both common paths and corner cases.
Implementation Details
The design implements several key mechanisms to manage instruction execution:
Register Renaming
reg [NUM_REGISTERS-1:0] reg_busy;
reg [INSTRUCTION_WIDTH - 1:0] reg_producer [0:NUM_REGISTERS-1];
This mechanism eliminates false dependencies and enables parallel execution of independent instructions.
Dependency Tracking
reg [INSTRUCTION_WIDTH - 1:0] src1_dep [0:NUM_INSTRUCTIONS-1];
reg [INSTRUCTION_WIDTH - 1:0] src2_dep [0:NUM_INSTRUCTIONS-1];
The design maintains precise tracking of instruction dependencies, ensuring correct execution ordering while maximizing parallelism.
Synthesis Results
The implementation was successfully synthesized using Cadence Genus.
Detailed reports covering area utilization, power analysis, and timing are available in my GitHub repository.
Future Enhancements
Several opportunities for enhancement exist:
- Integration of store operations
- Implementation of branch prediction
- Addition of cache hierarchy
- Support for floating-point operations
- Integration with a processor
Conclusion
This implementation demonstrates the enduring relevance of Tomasulo’s Algorithm in modern processor design. The project combines classic computer architecture principles with modern hardware description languages and verification methodologies.
The complete source code, test cases, and detailed reports are available in my GitHub repository. I welcome discussions about the implementation details and potential improvements.